

Over the years data has continued to explode in volume. With the advent of the Internet of Things (IoT) the avalanche of data continues to get even bigger and at much faster speed. Given the present scenario, organizations have two options: ignore this data or leverage it to enhance their competitiveness.
In general, the business users of today are much savvier and on the lookout for ways to leverage the existing data. The Bring Your Own Device (BYOD) is evolving to Bring Your Own Tool (BYOT). Tools available to users help analyze data, to see patterns, generate permutations and make predictions.
Traditionally, the only source of data used to be computer applications. Today, data hits organizations in varied shapes, sizes and forms; examples include mails, spreadsheets, video & audio files, machine generated data and voice activated devices like Alexa. With this bombardment of data, business users are not willing to wait upon for IT to provide them with what they are looking for. The traditional data storage methodologies, in any case, are incapable of ingesting such wide variety of data and catering to these users.
Traditional Data Storage Challenges
Timeliness. Adding data to a database or a data warehouse is time consuming and, in many cases, a convoluted process. Users do not have the time it takes to extract data from traditional data storage systems such as data warehouses.
Flexibility. Users not only want immediate access to data, but also want to use their own tools. Gone are the days when IT could limit the tools that users could use. In today’s day and age, users not only have the wherewithal to get the tools, they also have the ability to use these tools.
Data Types. Traditionally, there has been one type of data – raw numbers and words. Today’s data is varied and emanates from sources ranging from applications to mobile devices. Traditional data storage systems are ill equipped to handle all of this variety.
Retrieval. Getting to the data is as important as the data itself. Traditional data storage solutions simply assumed that the person trying to get access was an IT professional with knowledge of software development and related tools. In the present context, this no longer applies.
The Solution
The solution must address all of the above shortcomings and more.
- Support multiple reporting tools
- Self-serve
- Enable rapid ingestion of different types of data with no data manipulation or mapping
- Be flexible to support data analytics
- Embody easy search ability
The solution that can embody all of the above is Data Lake. Data Lake is the latest in a set of tools designed to meet today’s data storage and access challenges.
The Data Lake Architecture
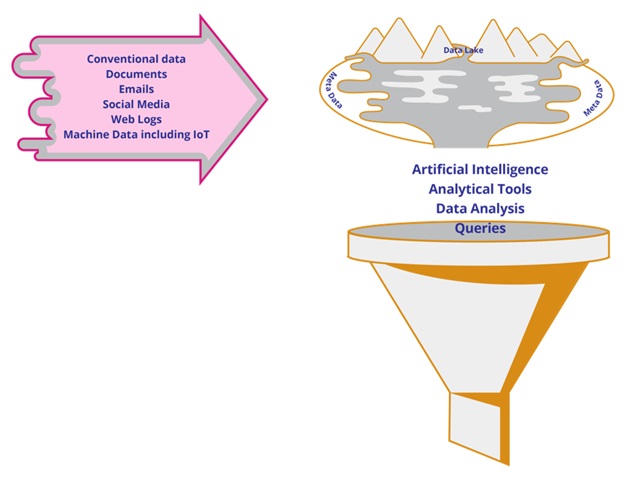 Data Lake is a data-centered architecture capable of storing unlimited data in various types of formats. Ingestions can happen in any form. This can range from traditional data i.e. user entry to audio and video files. Curation happens through extraction and separate storage of the meta-data.
Data Lake is a data-centered architecture capable of storing unlimited data in various types of formats. Ingestions can happen in any form. This can range from traditional data i.e. user entry to audio and video files. Curation happens through extraction and separate storage of the meta-data.
Data is ingested into the Data Lake in real time. Since there is no schema that data must follow, it lives in its original form in the Data Lake. Sitting on top of all of this is the analytical options. IT provides users the tools through which data can be analyzed. The users also have the option to pick their own choice of tools to use. Role of IT is increasingly changing from being in Information Technology to being in Data Technology. It now encompasses building of infrastructure and capture and storage of data for users who act as analysts and consume this data without the support or intervention of IT.
How do users interact with a Data Lake?
- The user browses through a Data Lake Service List.
- They pick and choose the data they are interested in and add it to their virtual shopping cart.
- They then use the tool of their choice to analyze the data.
- Users garner the required information which they may publish or use to make decisions.
- In addition to the above functionality, users also have the option to store their results in the Data Lake for the organization to use.
Designing & Implementing the Data Lake
Designing a Data Lake is an intensive endeavor. It needs strong technical expertise and a clear definition of the organization’s requirements. IT and Business must work very closely when designing it. A Data Lake implementation is best approached conservatively, instead of on a large scale.
- Document the goals a Data Lake is expected to achieve; define success.
- Define the library of services which must be provided.
- Design the hardware architecture on which the Data Lake will live.
- Document the tools which will be used to get to the data.
- Execute a Proof of Concept to confirm the viability.
- Fine tune.
- Release to users.
- Govern the Data Lake.
- Once it proves to be successful, expand the Data Lake.
Typical Data Lake design, creation & implementation team
A Data Lake design, creation & implementation team encompasses skills from across the organization.
- Project Manager. 1
- Data Scientist. 1 ~ 2
- Big Data engineers. 1 ~ 2
- Infrastructure Engineers. 1 ~ 2
- Business Users. 4 ~ 6
- Data Analytics/Science users. 2 ~ 3
- Governance users. 2 ~ 3
Characteristics of a user-friendly Data Lake
IT Independent. Users do not rely on IT to use the Data Lake. They know how to get to the data, how to use specific tools, and how to understand the results.
Domain specific. Data Lake is built just like traditional data storage built around the domain. In fact this process is even more significant for Data Lake since it does not require an of IT intervention for a user to use Data Lake. It is essential that the data elements of Data Lake relate to the business terminology. If users do not understand the data, they will not trust or use it.
Quality meta-data. The success of any data storage platform including, Data Lake, is the user’s ease searching for the data. Internet is not powerful because it contains so much data. It is powerful because users can access the data on their own by initiating searches in plain English and in terminology they understand. Similar rules apply for a well-designed Data Lake. It is important that the data which goes into the Data Lake must go through a process in which the meta-data is correctly captured.
Easy to expand. Leaves room for new data sources to continue to spring-up in every organization. A well designed Data Lake will allow IT to quickly add such sources without going through a lengthy wait. Data Lake will seamlessly integrate into the existing environment.
Data lineage. Many users lose trust in data if they cannot understand or determine the source. It is important to show the source and history of where the data emerged from.
Analytical tools. One of the goals of Data Lake is to empower the users by giving them the ability to analyze and question the data. But it is not something the users can achieve overnight. Data types can be added as the users get more familiar with the tools and the data.
Weaknesses in Data Lake
Incomplete data. In a Data Warehouse the data is cleaned and consolidated before it is saved. But in this process the, organization may lose information which is required for analysis. In trying to cleanse the data, and in trying to make it better by removing the anomalies and standardizing it, valuable information may be lost.
Fixation on data ingestion. Data Lake is only as good as the data in it. Dumping data into Data Lake and simply storing it without using will turn it into a data swamp.
Over governance. One of the goals of Data Lake is to provide ease of accessibility of data and analytical tools. Businesses value the flexibility all this provides. But governance is required to ensure the viability of data and tools. This fine line between the ease of accessibility and governance must be managed.
Production risks associated with a Data Lake
GIGO. This old adage of information systems is as true today as it was a century ago; GIGO – garbage in garbage out. Unlike traditional data storage which has built-in mechanism to ensure data coming in is clean, Data Lake by its very nature allows all kinds of data to come in. Governance has to be in place to ensure the quality and consistency of data. If standards are not upheld, Data Lake could turn into data pit and trust and usability with businesses would be lost.
Poor accessibility. Providing businesses their own tools is great, but this could turn into a risk for Data Lake if these tools are not effective in giving access to the data in ways that businesses want. The selection of tools is very important and must be monitored.
Data security. A well designed Data Lake is akin to crown jewels. If hackers get to it, they can get to know everything about the company. Since users can choose their own tools, the security risks are event greater.
Conclusion
Data Lake is an efficient and effective solution to address the data-avalanche which organizations are facing today. It is of interest to savvy organizations who want to channel the power of data to rise above the competition.
Unlike other technologies which basically automate an existing process, stabilize the IT environment, or create an incremental improvement, the creation and implementation of a Data Lake leapfrogs the organization ahead of the competition. Taking the approach of wait & see, instead of adapting to the new technological approaches is unlikely to help companies stay competitive. A well designed & trusted Data Lake in the hands of savvy users is bound to empower the organization. Of course the creation and implementation must be done thoughtfully with the help of detailed planning and input from the Business.

Deepak Sharma
Deepak Sharma is the Global IT Director with Agility. His portfolio includes the leadership of digital initiatives such as Data Lake, IoT and Artificial Intelligence. Deepak has over 3 decades of IT experience spread across multiple countries in establishing technology centers, product development and implementation of ERP systems.




